
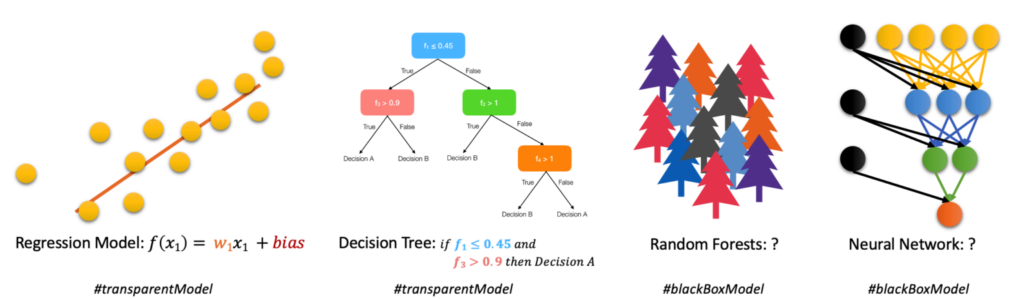
As businesses across the globe accelerate their digitalisation efforts, they are increasingly captivated by the power of artificial intelligence (AI) and machine learning (ML). Companies, especially those new to AI and ML, are often intrigued by the allure of complex models which promise high performance and prestige. Business often proudly announce that they use “haute couture” ML techniques such as random forests, support vector machines, neural networks, K-means clustering and boosting.
This idea is not difficult to wrap your head around. Let’s be honest: as a Data Science Consultant, who would not be tempted to tell potential clients that they will be using a “support vector machine with infinity kernel” instead of a logistic and a “least absolute shrinkage and selection operator” regression, instead of a linear regression. Complex technologies are often considered to have extraordinary capabilities and tell compelling narratives of success.
Life-saving simplicity
However, a trend towards “state of the art” models overlooks one crucial question: do we actually need them? Think about this: if you had to put a campfire out, would you prefer to mobilise a thousand firefighters and a helicopter ,able to airlift a water tank, or would you rather reach for a nearby bucket of water? Is the goal not just to extinguish the fire and would a bucket not accomplish the same goal? The same concept applies to the world of machine learning: are complex models necessary for driving business success?
Black boxes
Questioning necessity is especially important as complex models come with a trade-off: they are often a “black box”. The underlying mechanism and computation are difficult, sometimes near impossible, to understand. Given input data, the model gives predictions as output, without knowing for certain what happens in between. Since business decisions are high-stake by nature, this uncertainty poses a risk.

Business decisions require accountability, trust, and an understanding of the underlying reasoning. Imagine making a million-dollar investment based on a prediction from a model you don’t understand. It is as if you are driving blindfolded on a high-speed highway. You might be able to drive straight for a while with help, but would you take the risk?
To further illustrate, consider an e-commerce company that is trying to increase sales by recommending products to its customers based on their browsing and purchasing history. A complex model, such as a convolutional neural network, is able to provide highly personalised product recommendations and potentially drive up sales. However, this model is a “black box”. It churns out recommendations, but it does not provide insights as to why it recommends a certain product to a particular customer.
Imagine a scenario where a customer who has only ever purchased cat food suddenly receives a recommendation for a high-end camera. If the customer questions the recommendation, the company would not be able to provide a satisfactory explanation. This could lead to confusion, mistrust, and a loss of engagement. More importantly though, by understanding why certain products are recommended more than others. The e-commerce company can gain valuable insights into customer behaviour.
These insights can help drive marketing strategies. For example, if the model shows that customers who buy cat food are more likely to purchase certain types of cat toys, the company could recommend cat toys to these customers, or decide to offer a bundle deal combining cat food and cat toys, attempting to increase sales.
Opting for simple
To help identify clear patterns in a customer’s purchase history, a simpler and more interpretable model such as a rule-based recommendation system can be used. It could, for instance, identify that a customer buys dog food every month, and therefore recommend products popular among dog owners. Although it might not offer the same level of personalisation, there is an argument to be made for interpretability. Interpretability is crucial for model debugging and improvement. If a model is making consistent errors, understanding why it makes those errors is the first step towards improving it. If we are unable to interpret the model, the debugging process becomes akin to finding a needle in a haystack.
Complex models are often not as interpretable. This means that when they make a decision, it is difficult to understand why. If an AI model makes significant decisions, such as who gets a loan, who gets hired, or even who gets parole, the lack of transparency can be deeply problematic. It undermines accountability: when things go wrong, it is challenging to identify where and how the system failed. Moreover, there is a risk that decision-makers over-rely on complex models because they perceive them as all-knowing, without fully understanding them. This could lead to critical decisions being made without any human judgement.
While advanced models have their place and are undeniably powerful, the pursuit of complexity for the sake of complexity makes little sense and can lead us astray. Just because a model is complex and can yield high accuracy, it doesn’t necessarily mean it is the best choice for a given problem. In many cases, simpler models can be just as effective, if not more so. They can provide a good trade-off between interpretability and accuracy and can be much easier and cost-effective to implement.

Wait, we’re not done! Read part 2 on the advantages of both will be put side by side for a comparison.







