
Probability and statistics lie at the centre of data science. There are different ways of interpreting and expressing probability. Very often, it is expressed using the function P(), where P(a) defines the probability of event a. In this blog we will consider this probability function P() from two perspectives: a frequentist statistical approach as well as a Bayesian statistical approach.
These two perspectives are very different in how they handle uncertainty. In short, the frequentist perspective is more objective than the Bayesian one. It assigns probability based on data, whereas the Bayesian method takes the more subjective approach of incorporating hypotheses. These hypotheses, often called “beliefs” in Bayesian theory, are updated each time new information becomes available. Bayesian methods have become more and more “hip”, but is that justified? This blog will introduce you to Bayesian statistics and provide an overview of its pros and cons when compared to frequentist statistics.

Bayes’ Rule
When working with data, Bayesian probability theory often feels like a more intuitive way of defining probability. Instead of depending on a known probability distribution, it depends on drawn data. Hence, this provides convenience when working with data with unknown probability distributions, which is very often the case. At the core of Bayesian statistics we find Bayes’ Rule, a fundamental principle that allows us to update our beliefs or probabilities about an event based on evidence. This is done through conditional probability, which represents the probability of an event occurring given that another event has already occurred. For example, we can define P(rain | clouds), the probability that it will rain, given that there are clouds.
Definition Bayes’ Rule: Let A and B be the events in the same probability space with P(B) ≠ 0, then
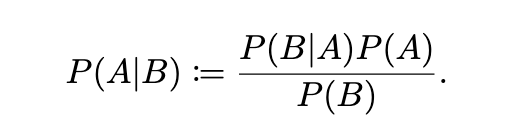
Now we can rewrite A=belief and B=data, such that the above equation is easier to understand.
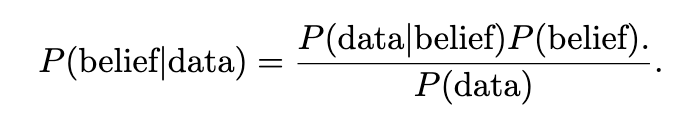
Bayes’ Rule has four parts:
- P(belief) = prior,
- P(data | belief) = likelihood,
- P(belief | data) = posterior,
- P(data) = marginal likelihood
Steps
In Bayesian statistics, we try to make an educated guess for the prior (1), our belief. Once we start gathering data and learn about its distribution, we can calculate the likelihood (2) and use it to update our prior. The updated version of our prior is called the posterior (3). In practice we do not always need the marginal likelihood (4) and can consider it a constant. It normalises the posterior P so that we can ensure P to be a probability between 0 and 1.
In other words, we:
- Define a prior belief,
- Gather data to calculate the likelihood
- Update our prior with this new information to get our posterior
Explaining Bayes’ popularity: Bayesian Pros
As explained before, a big advantage of the Bayesian approach is its iterative nature. We can select a prior, update it to a new posterior based on new data, use it to define a new prior and update it once again to find a new posterior. With this method, we can gain confidence on the probability distribution of unseen data as we get to see more of it. It provides an intuitive way of handling uncertainty in the context of data. What’s more, this method allows for reasoning about data before seeing it all.
In the context of A/B-testing, for instance, this can be very useful. So-called “early stopping” makes it possible to discontinue testing when we consider it finished, saving time and other valuable resources. It is easy to understand why so many companies opt for Bayesian methods, and why businesses are considered less old-fashioned when doing so. Or is it?

The case for Frequentist: Bayesian Cons
The main counterargument against the Bayesian approach is its subjective nature, as it is highly dependent on the chosen prior. Different individuals may specify different priors, based on different information. Priors that are too subjective will likely fail to provide accurate, objective conclusions. A high-quality prior, essential for a high-quality posterior, is hard to select. Unfortunately, those responsible for constructing priors are often not the ones most capable in Bayesian statistics. Bayesian statisticians are very rare and are often not the ones with expert knowledge on the problem at hand. This knowledge gap, combined with the inherent complexity of Bayesian statistics, makes successful and effective execution of the Bayesian approach a rarity.
Moreover, while interpretation of Bayesian probability may seem intuitive, carrying out its computations is extremely complex. Very often, these Bayesian calculations require computation of many complex integrals. Its iterative nature only adds to this complexity. Thus, performing Bayesian analyses the proper way will take programmers lots of time and could cause lots of computational debt. Additionally, the aforementioned “early stopping” might seem very useful but be less effective in practice. People often do not know the intricacies of Bayesian statistics and are not able to foresee the consequences of these actions. An A/B-test might be stopped early when the posterior looks promising, even without considering clear biases. However, changes to a website might very well turn out to be less promising than the results of the test have suggested. One should be careful and study the consequences of certain assumptions when applying the Bayesian framework.

Conclusion
Although the Bayesian approach is indeed a powerful tool for many theoretical and practical problems, its limitation is often seriously underestimated. Because of its high complexity, it could often be a good idea to opt for the old-fashioned Frequentist approach, avoiding conceptual confusion altogether. What do you think? Do the upsides discussed in this blog outweigh the many downsides for your company? Or has the Bayesian approach become too “hip and trendy” to make use of?






